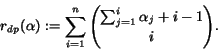Therefore, it is possible to bijectively enumerate the monomials in the order given by the monomial ordering and to represent an entire monomial by just a single integer, which we call the rank of a monomial.
The bijective maps between the monomials and the integers depend on the used monomial ordering: for the degree reverse lexicographic ordering it is given by the following lemma:
Lemma 2:
Let
![]() and
and
![]() given by
given by
A similar bijective map can be given for the ordering Dp (degree lexicographic). For negative orderings like Ds or ds the same idea can be exploited but it is necessary to change the signs since the zero monomial is, with respect to these orderings, the largest, not the smallest monomial.
Using the rank-based representation for monomials, monomial comparisons can very easily and efficiently be realized by simply comparing their corresponding ranks (we also call such monomial comparisons simply rank-based comparisons). Furthermore, a pure rank-based polynomial representation is very compact, i.e. requires an almost minimal amount of memory. Unfortunately, we have to pay for these advantages with the following difficulties:
| variables | 3 | 4 | 5 | 7 | 10 | 15 | 20 | 25 |
| max. deg | 2340 | 471 | 186 | 66 | 31 | 17 | 12 | 9 |
Problem (i) is overcome in the Macaulay system by keeping two representations of the the leading monomial of a polynomial (the integer representation and the exponent vector representation) and by computing the inverse of the enumeration map for the non-leading monomials of a polynomial.
Problem (ii) is overcome by restricting the input polynomials to being homogeneous and by Macaulay's ``infamous'' degree bound messages and enforcement mechanisms.
Problem (iii) is simply ignored by Macaulay -- no computations with non-degree orderings are possible.
In SINGULAR, we choose a slightly different way to overcome problems
(i) - (iii): first, we always keep the exponent vector representation
of a monomial. And, second, if a monomial is smaller than the maximal integer
monomial, we store its rank in the negative range
of the order field (i.e.,
a->order + INT_MAX yields the rank of the monomial
a). If, on the other hand, a monomial is larger than the
maximal integer monomial, then its order field contains (as
before) the (positive) degree of the monomial.
Based on such a data representation, monomial comparisons can simply be accomplished as follows:
inline long MonComp(Term_t* a, Term_t* b)
{
if (a->order != b->order)
{
if (a->order > b->order) return 1;
return -1;
}
// a->order==b->order: are we already done?
if (a->order < 0) return 0; // monom's are equal
/* now compare using the exponent values,
assuming the degrees are equal ... */
}
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Notice that we do not need to distinguish between the two different
interpretations of the order field: if we compare a monomial
which is smaller than the maximal integer monomial (order
value is negative) with one that is larger (order value is
positive), then the different signs of the order fields result
in an immediate and correct return of the monomial comparison.
Therefore, only a sign-check (for the case of equal order
fields) needs to be added to the previously given monomial comparison
routines to have them take advantage of ranks.
Since we always keep the exponent vector representation alongside with
the ranks, monomial divisibility tests and additions can be
accomplished as usual, except that we need to recompute and set the
order field at the end of the monomial addition routine. For
monomials smaller than the maximal integer monomial, this basically
amounts to computations of the respective ranks. We
accomplish the latter by a simple implementation of (6)
using a pre-computed table of binomial coefficients.
As with vectorized monomial additions, overflow or degree checks can largely be moved to the outer loops of the GB computations so that we can almost always avoid the costly checks on whether or not the sum of two monomials is smaller than the maximal integer monomial.
As a summary, we can conclude that with a relatively small effort, it is possible to extend a ``traditional'' exponent vector-based monomial representation so that it can fully take advantage of ranks while, at the same time, the limitations of the Macaulay system (degree bounds, no support for non-degree orderings, repeated inverse rank computations) can be avoided.
But now again, let us examine some timings (Table
2) to see how much all that buys us in practice: we
again used the examples of the Appendix and performed all GB
computations using the degree reverse lexicographical ordering (dp)
over the coefficient field
Z/32003. We obtained timings
for three basic SINGULAR configurations: char and short
exponents with vectorized monomial operations, and short
exponents with ``traditional'' (i.e., not vectorized) monomial
operations. For each of these ``conventional'' configurations, we also
obtained a SINGULAR version which uses rank-based
comparisons and measured the following:
And again, let us see what we can conclude from these experiments:
Firstly, rank-based comparisons are realized substantially faster than traditional and vectorized monomial comparisons (see the t</tr,< columns), except in such examples, where a majority of the monomials is larger than the maximal integer monomial (these examples are marked with a *).
Secondly, the time spent for rank computations during monomial additions is significant, and cannot be neglected (see the %R columns).
Thirdly, whether or not the time saved by rank-based comparisons pays off against the additional time spent for rank computations, depends on the relative efficiency of the ``conventional'' monomial comparisons and on the characteristics of the example -- where the percentage of time spent in monomial comparisons seems to be the most important factor (compare the %comp and t/tr columns).
Finally, evaluating the t/tr columns, we can conclude good news and bad news: the good news is that rank-based comparisons, by and large, lead to an overall speedup when used in combination with traditional (i.e., not vectorized) monomial operations. That is, our results make a strong case for such a usage of the rank-based representation. The bad news is, that rank-based comparisons by and large do not lead to an overall speedup when used in combination with vectorized monomial operations. Our results show that the more efficient vectorized monomial operations result in smaller speedups of the rank-based comparisons, i.e., speedups which are generally too small to outweigh the additional cost of computing ranks.